Skip to content
Annuaire Web
Les meilleurs sites
Navigation
sportmag.info
planete-beaute.com
geeknetwork.fr
jardiner-naturellement.org
legendesdusport.fr
car-only.com
parents-en-action.com
aliasimmo.fr
espace-senior.info
newsdeco.com
hebdolinux.org
tictacsport.fr
wedding-news.net
alter-ec-home.com
mon-guide-auto.fr
concept-deco.com
gourmandises-et-bavardages.com
financeimmo.fr
o-business.fr
france-mariage.fr
maison-immobilier.fr
belle-et-unique.fr
la-maison.info
conseil-au-jardin.fr
been-online.net
aide-auto.com
lespritdusport.fr
digitalenaive.fr
coups-de.net
mtm-france.com
foncier.net
activ-invest.fr
partenaire-immo.com
flow3.org
aujourdhui-jinvestis.fr
mon-blog-cuisine.com
voyageaupaysdesmerveilles.com
moncoachsportifenligne.fr
big-immo.com
blog-it.net
alternative-travel.net
unjoben24h.fr
encrages.org
must-car.fr
universmariage.com
leblogdevoyage.fr
mademoisellecaramel.fr
trouver-un-job.fr
comptoir-des-voyageurs.fr
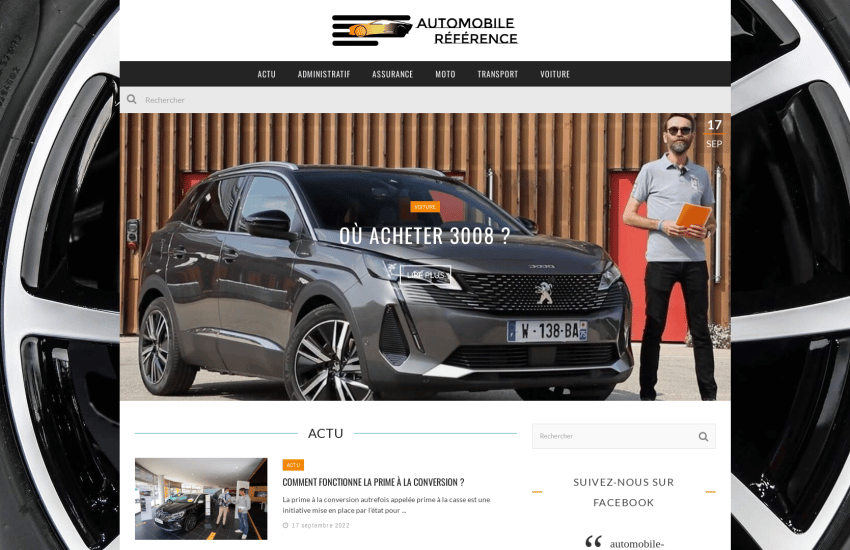
automobile-reference.com
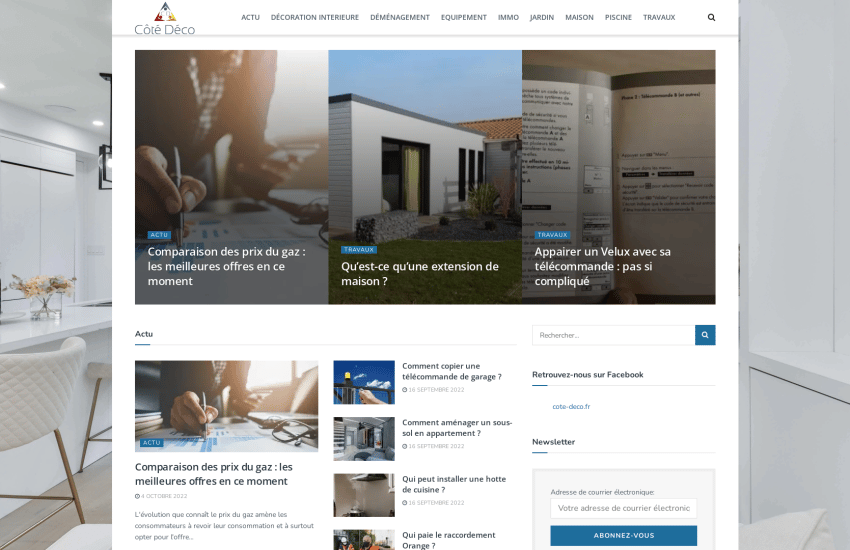
cote-deco.fr
generationentreprise.org
atmospheredujardin.com
motorcycleboy.fr
sportandform.fr
reussir-investir.fr
auto-tech.be
expert-jardin.fr
lepetitblogdemaman.com
momes-et-merveilles.fr
cityautomobiles.fr
france-actus.com
quelvoyage.fr
carburauto.fr
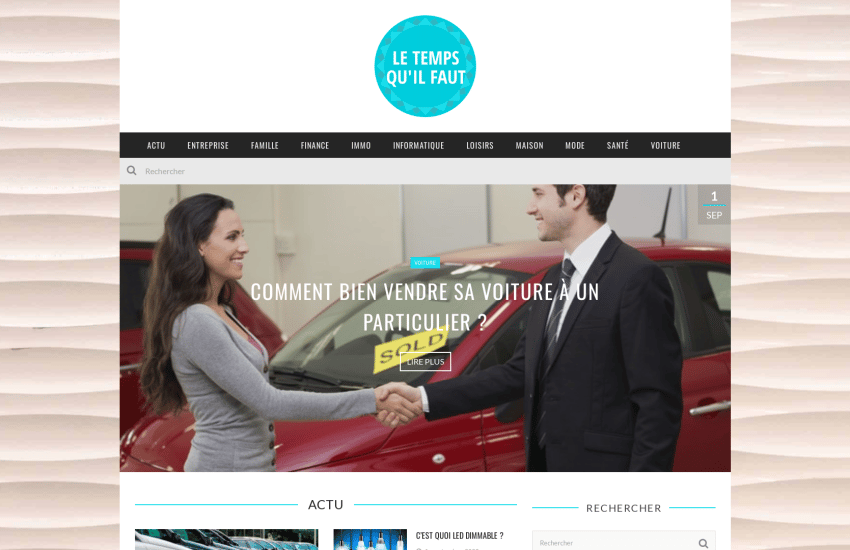
letempsquilfaut.com
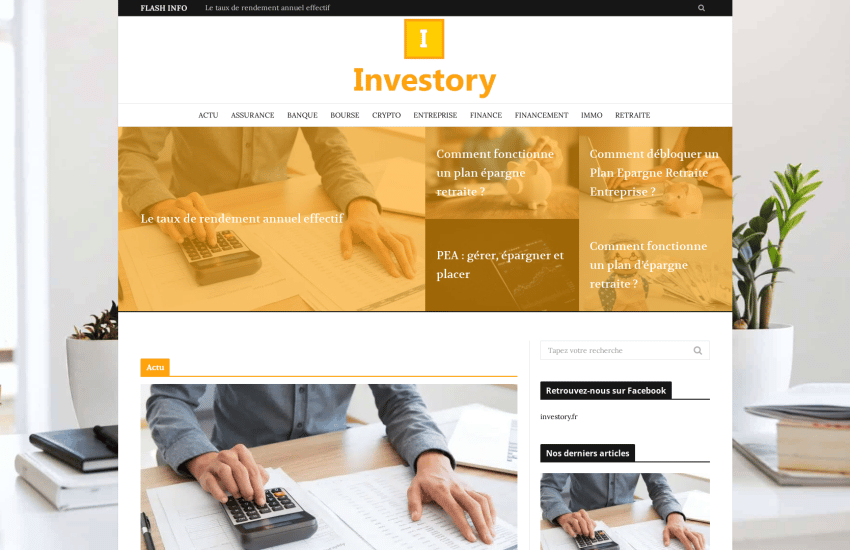
investory.fr
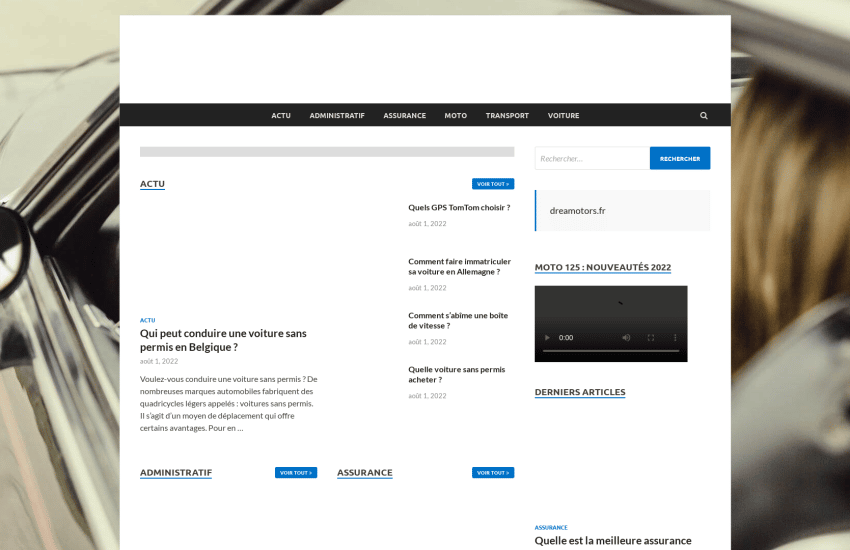
dreamotors.fr
comptoirdunet.fr
neonews.fr
immogenius.fr
mag-paris.org
team-auto-passion.com
informationinflux.org
jobassistant.fr
ze-news.fr
intereactive.net
chezjoelle.net
agiremploi.fr
pucker-up.net
blog-vip.net
destination-bretagne.fr
muchos.org
viruslab.fr
jvoiture.fr
aipdb.org
libreinfo.org
guide-entrepreneur.fr
retbutiko.net
orvinfait.fr
blospot.fr
moteurmag.com
mes-liens-favoris.net
ricci-art.net
blogmode.net
lesherosdusport.com
le-managemental.fr
lapetiterevue.fr
consultantweb.net
monconseillerdentreprise.fr
info-ler.fr